After several months of silence due to our team moving, finding a new home, and generally working really hard, we are happy to announce today that a new version of BinDiff is available! While the underlying comparison engine has only changed slightly, we have some significant improvements on the UI, and some improvements that are particularly useful for porting symbolic information from FOSS libraries into your disassemblies. In the following, I will highlight my favourite new features:
Call graph difference visualisation
With more complex differences between two executables, it is sometimes easy to miss the big picture by drilling down too much on changes to individual functions. With BinDiff 4.0, I now have the ability to not only examine changes on the level of the individual function, but also on the call graph. As with most UI improvements, an image is much more useful than a long diatribe; I will let the following screenshot speak for itself:

Examining changes on the callgraph level
Combined visualization of two flowgraphs
Ever since the very first version of BinDiff, the only way to examine a change in a flowgraph was by using our split-screen approach: One function on each side, laid out in a similar manner, with colors indicating changes. While this works pretty well (and is still my favorite way of looking at changes), it is sometimes a bit cumbersome. In the new UI, we added an additional way of examining changes: We merge the two graphs into one, and have a vertical split on the basic block / node level. This allows full-screen examination of changes without the need for splitting the screen.

The combined visualisation of changes
Iterative diffing
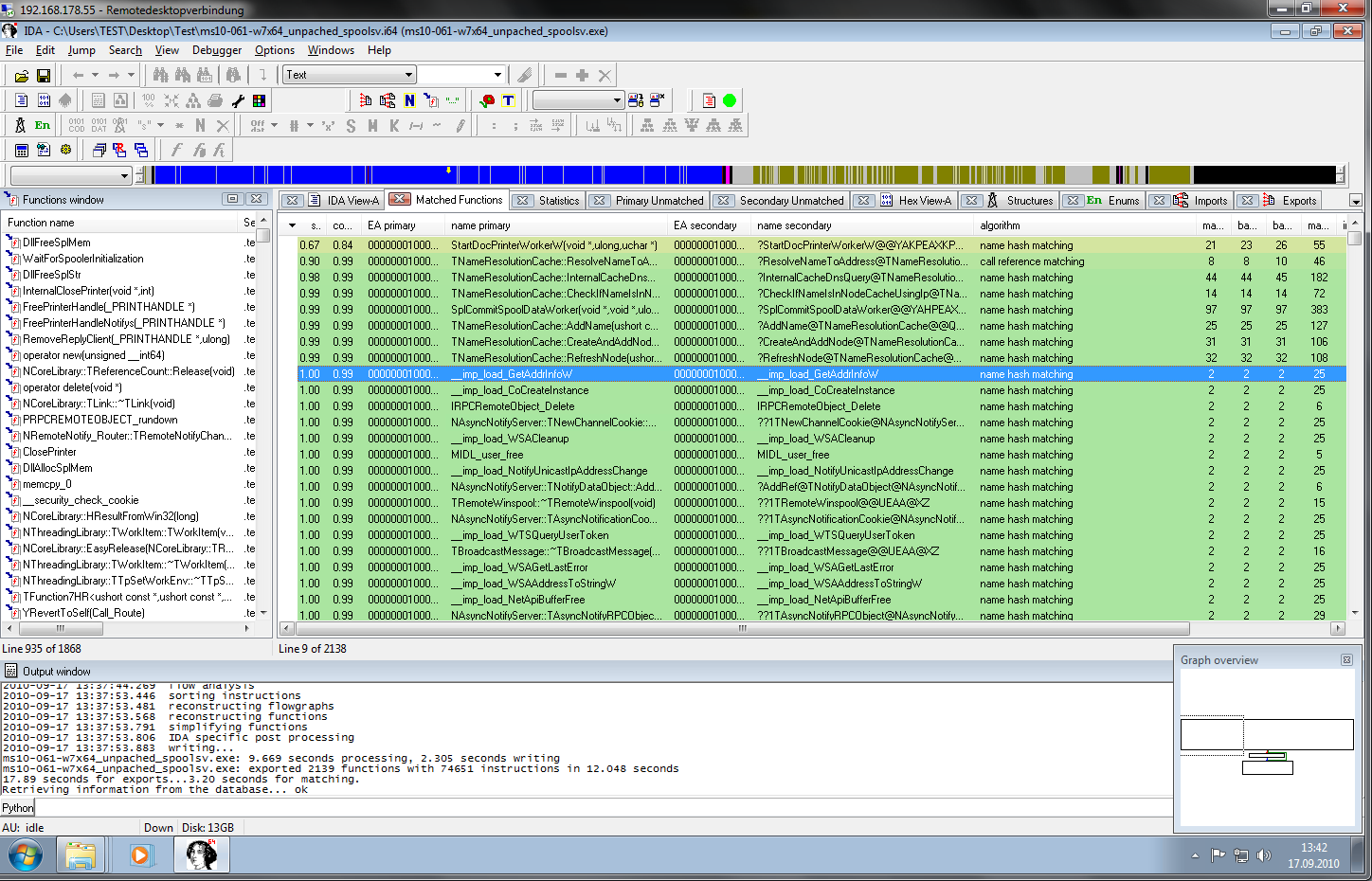
Over the last years, symbol porting has eclipsed patch analysis as my primary use for BinDiff. In many situations, I need to pull information from a FOSS project into an existing disassembly. I usually compile the FOSS project with symbols, attempting to approximate the build settings of the executable I am analyzing. I then BinDiff the disassembly against the compiled FOSS library and selectively import symbols and names for the functions that were recognized properly. While BinDiff often produces pretty good results, only a fraction of the functions will be recognized properly. In such situations, I often wished I could assist BinDiff infer further matches. With BinDiff 4.0, I can do just that: I can confirm that a pair of functions are matched correctly, and then tell BinDiff to re-run with the confirmed functions as starting points for further inference. This iterative approach allows me to match more and more functions while porting my symbols, yielding a much larger percentage of symbols in my disassembly than what would have been achieved in a single round of comparison.

Confirming a few matches

After confirming, click in the "Diff Database Incrementally" button
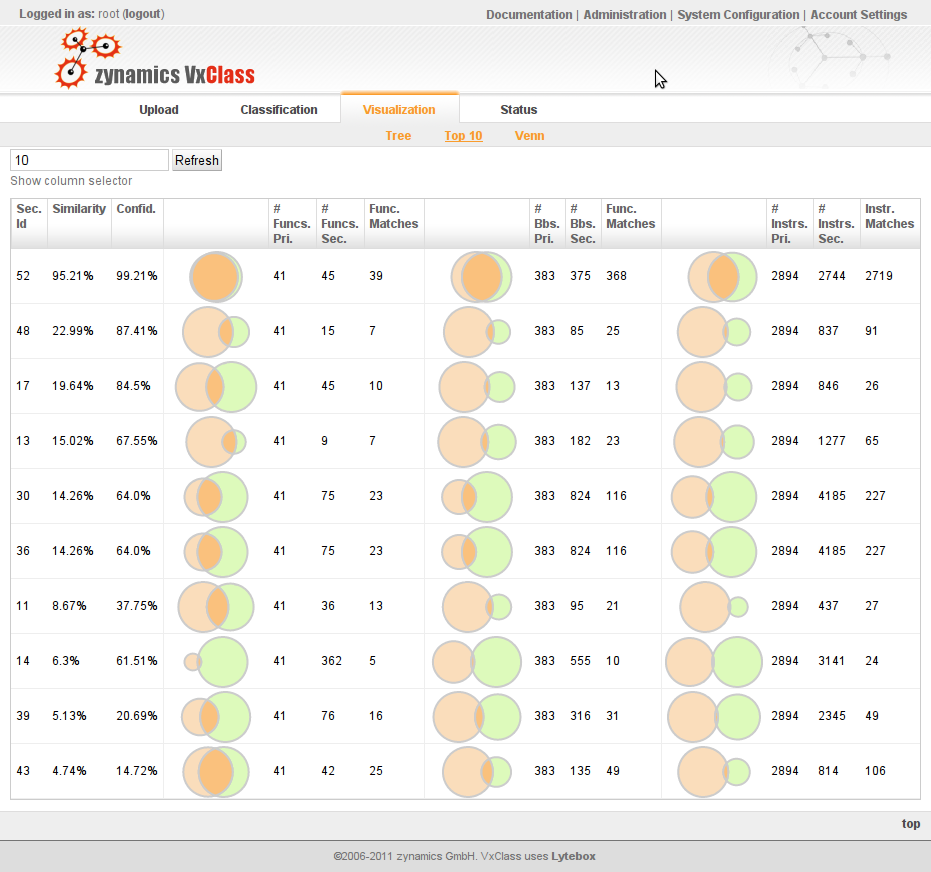
More Pie Charts
When comparing two pieces of related code, it is often useful to obtain a quick overview of the degree of code overlap between two files. What fraction of the functions in an executable could be mapped to the other executable? How similar were these functions? While all this information is available to BinDiff, up until the new version we never visualized this information in a central location. This has changed with the new UI – we now generate pretty pie charts, almost instantly usable in your favorite presentation software.

Pretty pies !
There are other new features in the UI – just give it a spin. After all, BinDiff is now directly available from our website and the price has been lowered to just 200 USD!






















{kind=link}